Pamphlets
Popularity/Prestige

If canonicity means escaping obscurity, we need a model of the canon that can accommodate multiple methods of being remembered. Download PDF
Totentanz. Operationalizing Aby Warburg’s Pathosformeln
The object of this study is one of the most ambitious projects of twentieth-century art history: Aby Warburg’s *Atlas Mnemosyne*, conceived in the summer of 1926 – when the first mention of a *Bilderatlas*, or “atlas of images”, occurs in his journal—and truncated three years later, unfinished, by his sudden death in October 1929. Download PDF | View project
Patterns and Interpretation

One thing for sure: digitization has completely changed the literary archive. Download PDF
Broken Time, Continued Evolution: Anachronies in Contemporary Films

After the economic ideology of “Bankspeak”, and the cultural geography of “The Emotions of London”, “Broken Time” is the Literary Lab’s first venture into film studies, to be followed by a pamphlet on art history: a series of investigations which we hope will contribute to establish a common conceptual ground among the different branches of quantitative cultural history. Download PDF
The Emotions of London
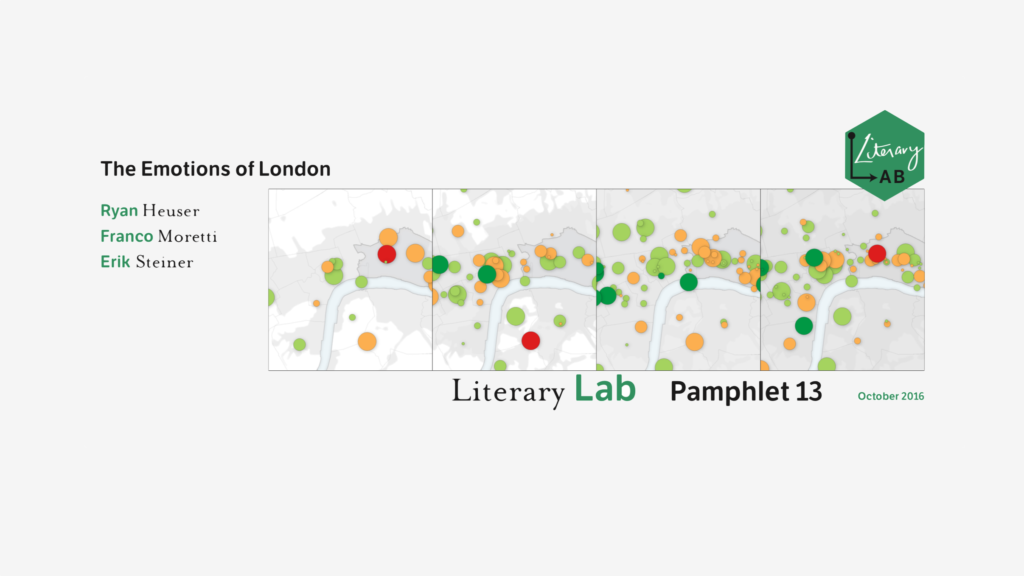
“The Emotions of London”, written by Ryan Heuser, Franco Moretti, and Erik Steiner, inaugurates a new field of work for the Literary Lab — that of literary and cultural geography. Working on a corpus of 5,000 novels, and covering the two centuries from 1700 to 1900, this pamphlet charts the uneven development of social spaces and fictional structures, bringing to light the long-term connection between emotion and class in narrative representations of London. Download PDF
Literature, Measured

In 2010, none of the five authors of “Quantitative Formalism” had any idea they were writing a “pamphlet”. A well-known scholarly journal had been asking for an article on new critical approaches, and that’s where we sent the piece once it was finished. But … Download PDF
Canon/Archive. Large-scale Dynamics in the Literary Field
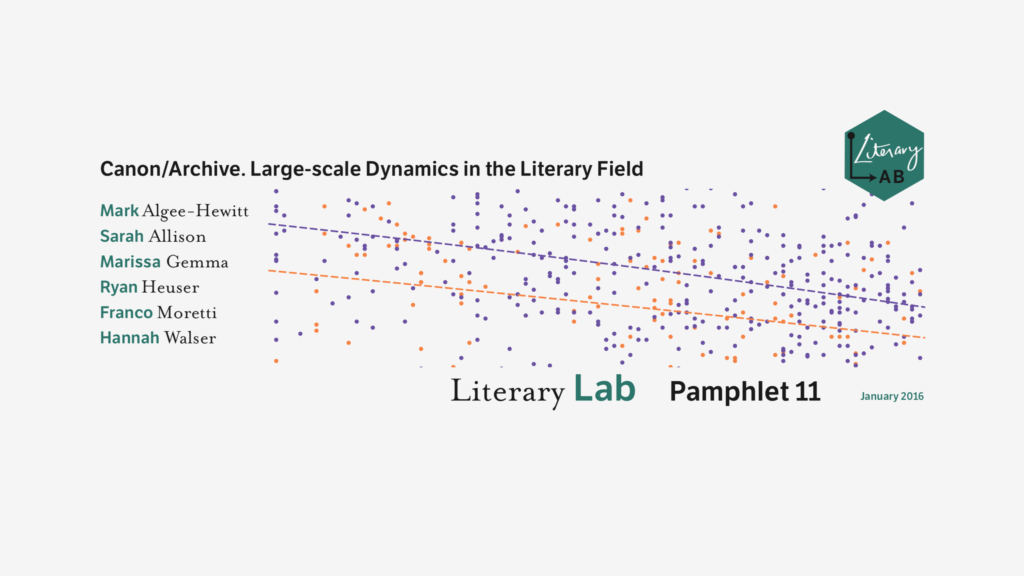
Of the novelties introduced by digitization in the study of literature, the size of the archive is probably the most dramatic: we used to work on a couple of hundred nineteenth-century novels, and now we can analyze thousands of them, tens of thousands, tomorrow hundreds of thousands. It’s a moment of euphoria, for quantitative literary history: like having a telescope that makes you see entirely new galaxies. And it’s a moment of truth: so, have the digital skies revealed anything that changes our knowledge of literature? Download PDF
On Paragraphs. Scale, Themes, and Narrative Form

Criticism has traditionally worked with the middle of the scale: a text, a scene, a stanza, an episode, an excerpt… An anthropocentric scale, where readers are truly “the measure of things”. But the digital humanities, Alan Liu has written, have changed the coordinates of our work, by “focusing on microlevel linguistic features […] that map directly over macrolevel phenomena.” Exactly. And how does one study literature, in this new situation? Download PDF
Bankspeak: The Language of World Bank Reports, 1946-2012

A literary historian and a sociologist of science analyze how the World Bank presents – and justifies – its role within the global economy. Focusing on the Bank’s semantic and grammatical patterns, Moretti and Pestre provide a path-breaking study of an “institutional” language, and of the neo-liberal rhetoric of recent decades. Download PDF | View project
Between Canon and Corpus: Six Perspectives on 20th-Century Novels

“Of the many, many thousands of novels and stories published in English in the twentieth century, which group of several hundred would represent the most reasonable, interesting, and useful subset of the whole?” Thus begins the latest Pamphlet of the Literary Lab, in which Mark Algee-Hewitt and Mark McGurl sketch out a broad, ambitious map of modern narrative in English. Laying bare the disparate systems of evaluation whose interactions define our objects of study, “Between Canon and Corpus” charts the inner dynamic of the 20th-century literary field in a newly sophisticated way. Combining network theory, book history, and literary sociology, Algee-Hewitt’s and McGurl’s research marks the Literary Lab’s first attempt to come to terms with the literary field as a unified, internally differentiated system: a line of inquiry to which we will devote increasing attention in the years to come. Download PDF | View project
Loudness in the Novel

The novel is composed entirely of voices: the most prominent among them is typically that of the narrator, which is regularly intermixed with those of the various characters. In reading through a novel, the reader “hears” these heterogeneous voices as they occur in the text. When the novel is read out loud, the voices are audibly heard. They are also heard, however, when the novel is read silently: in this latter case, the voices are not verbalized for others to hear, but acoustically created and perceived in the mind of the reader. Simply put: sound, in the context of the novel, is fundamentally a product of the novel’s voices. This conception of sound mechanics may at first seem unintuitive—sound seems to be the product of oral reading—but it is only by starting with the voice that one can fully appreciate sound’s function in the novel. Moreover, such a conception of sound mechanics finds affirmation in the works of both Mikhail Bakhtin and Elaine Scarry: “In the novel,” writes Bakhtin, “we can always hear voices (even while reading silently to ourselves).” Download PDF | View project
“Operationalizing”: Or, the function of measurement in modern literary theory

An uncommonly ungainly gerund, “operationalizing” is nevertheless the hero of the pages that follow, because it refers to a process which is absolutely central to the new field of computational criticism, or, as it has come to be called, of the digital humanities. Though the word is often used merely as a complicated synonym for “realizing” or “implementing”—the Merriam-Webster online, for instance, mentions “operationalizing a program”, and adds a quote on “operationalizing the artistic vision of the organization”—the origin of the term was different, and much more precise; and for once origin is right, this is one of those rare cases when a word has an actual birth date: 1927, when P.W. Bridgman devoted the opening of his *Logic of modern physics* to “the operational point of view.” Download PDF | View project
Style at the Scale of the Sentence

… But could the different frequencies of “she” and “you” and “the” really be called “style”? On this, we disagreed. Some of us claimed that, though all styles do indeed entail linguistic choices, not all linguistic choices are however enough to speak of a style; others countered this argument by stating that, once an author or a genre opts for a certain linguistic choice, this is really all we need for our analysis, as a style follows necessarily from this fundamental level. This was the genuinely reductionist position – style as nothing but its components – and the more logically consistent one; the other position admitted that it couldn’t specify the exact difference, or the precise moment when a “linguistic choice” turned into a “style”, but it insisted nonetheless that reducing style to a strictly functional dimension missed the very point of the concept, which lay in its capacity to hint, however hazily, at something that went beyond functionality. Our job should consist in removing the haze, not in disregarding the hint. Download PDF
A Quantitative Literary History of 2,958 Nineteenth-Century British Novels: The Semantic Cohort Method

The nineteenth century in Britain saw tumultuous changes that reshaped the fabric of society and altered the course of modernization. It also saw the rise of the novel to the height of its cultural power as the most important literary form of the period. This paper reports on a long-term experiment in tracing such macroscopic changes in the novel during this crucial period. Specifically, we present findings on two interrelated transformations in novelistic language that reveal a systemic concretization in language and fundamental change in the social spaces of the novel. We show how these shifts have consequences for setting, characterization, and narration as well as implications for the responsiveness of the novel to the dramatic changes in British society. This paper has a second strand as well. This project was simultaneously an experiment in developing quantitative and computational methods for tracing changes in literary language. We wanted to see how far quantifiable features such as word usage could be pushed toward the investigation of literary history. Could we leverage quantitative methods in ways that respect the nuance and complexity we value in the humanities? To this end, we present a second set of results, the techniques and methodological lessons gained in the course of designing and running this project. Download PDF
Becoming Yourself: The Afterlife of Reception

If there is one thing to be learned from David Foster Wallace, it is that cultural transmission is a tricky game. This was a problem Wallace confronted as a literary professional, a university-based writer during what Mark McGurl has called the Program Era. But it was also a philosophical issue he grappled with on a deep level as he struggled to combat his own loneliness through writing. To really study this question we need to look beyond the symbolic markets of prestige to the real market, the site of mass literary consumption, where authors succeed or fail based on their ability to speak to that most diverse and complicated of readerships: the general public. Unless we study what I call the social lives of books, we make the mistake of keeping literature in the same ascetic laboratory that Wallace tried to break out of with his intense authorial focus on popular culture, mass media, and everyday life. Download PDF
Network Theory, Plot Analysis

In the last few years, literary studies have experienced what we could call the rise of quantitative evidence. This had happened before of course, without producing lasting effects, but this time it’s probably going to be different, because this time we have digital databases, and automated data retrieval. As Michel’s and Lieberman’s recent article on “Culturomics” made clear, the width of the corpus and the speed of the search have increased beyond all expectations: today, we can replicate in a few minutes investigations that took a giant like Leo Spitzer months and years of work. When it comes to phenomena of language and style, we can do things that previous generations could only dream of. When it comes to language and style. But if you work on novels or plays, style is only part of the picture. What about plot – how can that be quantified? This paper is the beginning of an answer, and the beginning of the beginning is network theory. Download PDF | View project
Quantitative Formalism: An Experiment

This paper is the report of a study conducted by five people – four at Stanford, and one at the University of Wisconsin – which tried to establish whether computer-generated algorithms could “recognize” literary genres. You take David Copperfield, run it through a program without any human input – “unsupervised”, as the expression goes – and … can the program figure out whether it’s a gothic novel or a Bildungsroman? The answer is, fundamentally, Yes: but a Yes with so many complications that make it necessary to look at the entire process of our study. These are new methods we are using, and with new methods the process is almost as important as the results. Download PDF | View project