Virtual Readers
Mark Algee-Hewitt; Aug 25, 2016
Often, the most exciting moment of a Lab project occurs when our research takes an unexpected direction: we thought we were doing 'a', but it turns out that all along we've been doing 'b' (or, more often, should have been doing 'b'). The realization that we've discovered something unexpected, the ability to be guided by the research and its results: these are what differentiates a Lab project from the traditional pursuits of the humanities. And nowhere is this turn more obvious, more frustrating and yet rewarding, than when it occurs at the level of method: when a project whose underlying technology, such as principle component analysis, or sequence matching, proves frustratingly elusive to the data only to suddenly fall into place when one of the project participants points out that our data looks more like something that would respond to, for example, information theory or topic modeling. In such cases, more often than not, we realize that we can now think about the research entirely differently and that what we had expected and hoped to find with our original method is much less interesting than what we now can discover, seemingly by accident.
The Lab's project on suspense literature underwent one such reversal midway through our research. Our initial goal in the project was to look for formal features in texts that were associated with the experience of suspense on the part of readers (whether or not they were actually causal), and our initial methods were largely exploratory and heavily informed by our assumptions as to what we might find. In our first attempts, we created features sets (effectively semantic fields) and traced their frequency through the narratives of novels from our hand-assembled suspenseful and unsuspenseful corpora. Despite finding a few promising moments of correlation between various topics and some potentially suspenseful moments in certain narratives (as identified and tagged by readers), we were left stymied by the sheer variety of features and types of suspense. It wasn't until one member of the group suggested (in jest) that it would be much easier if we could use our features to create a suspense detector that the project became clear. We realized that we had been thinking about our data in the wrong way. Rather than create graphs of semantic fields across narratives and try to interpret them ourselves, what if we had a computer create a model based on the patterns that were too subtle for our readerly comprehension? Then we could investigate the choices that it made to identify the patterns that seemed to be indicative of suspense.
This move, from an exploratory, cluster based approach to one predicated on a classification model fundamentally shifted how we saw the project. In the former, the heuristic model is much more familiar to traditional humanities research: the computer transforms the data and then we use our own critical eye to recognize patterns in the data derived from the texts.[1] In the latter, we surrender the reading process to the computer and, by watching how the algorithm makes its decisions as to what a suspenseful passage is and what features indicate its presence, we identify the groups of features, and patterns that we had sought from the beginning. We can then judge these computer derived patterns against our critical knowledge on suspense literature. As an added benefit, the success or failure of the model would also indicate how strongly our selected formal features were indicative of the readerly perception of suspense.[2]
But now that we had decided to make the move from clustering to classification, we were left with a new decision: what classification model would work best, given our somewhat unorthodox data? For our features, we had assembled 87 significantly distributed topics (out of a 150 Gibbs topic model of our suspense and unsuspense corpora), a list of words distinctive of our suspense corpus and a related list of words distinctive of our unsuspense corpus. To this we also added the average age of acquisition (AoA) scores of the texts, and distinctive words of suspense and unsuspense in a smaller short story corpus. We measured each of these fields in over 800 passages that had been hand rated for suspense by a group of readers (our passages were 2% slices of the text in a moving window advanced by 1%).[3] Initially, many more passages had been rated on a scale of 1 to 10 by members of the group, but for this analysis, we only kept those scored below a 3 or above a 7, to create a binary response variable of either 'suspense' or 'unsuspense.' Given our new goal, what we needed was a model capable of combining these features sets, which varied from an average of 23 words per topic field and between 3000 and 4000 for our distinctive word fields, not to mention age of acquisition scores, into a coherent model.
Our first attempts, using the familiar classificatory models of logistic regression, discriminant function analysis (DFA) and support vector machines (SVM), failed. None classified with an accuracy of more than 65% (using a training sample of 75% of our data, cross-validated with a test set of the remaining 25%). In fact, our most successful model was the SVM, which simply classified all of our passages as suspenseful: due to an imbalance in our corpus between the suspenseful and unsuspenseful passages, this resulted in our 65% success rate (or, exactly equal to chance). Clearly, either our initial premise was wrong -- perhaps suspense was entirely located in reader's affect and experience -- or there was some complexity to our variables that resisted these classificatory models. We began to suspect that our features, especially given their diverse origins and unequal sizes, may not combine linearly with our response variables (e.g. a+b+c+d+e...) as the models assume, but may be non-linear (exponential, logarithmic, decaying or chaotic).
It was here that we hit upon the Artificial Neural Network (or ANN). Neural networks have become much more popular in recent large-scale complex modeling (such as Google's deepnet) or in word vector analysis (such as Word2Vec, where the relationships between the hidden nodes reveal relationships between words). Although our goals were much more straightforward, and our variables were much less complicated, the ANN offered a number of benefits over other classificatory models. Computationally, the advantage of the neural network lies in its ability to handle non-linear models As one of our eventual goals was to increase our feature set with even more diverse variables (measures of volatility, type token ratios, part of speech tags, narrative position, etc), we need our model to account, not just for our present set of variables, but for any that we chose to add in the future, whether continuous, categorical or something else. From a critical standpoint, too, the psudeo-cognative structure of the neural network suggested an intriguing resonance with the reader-focused aspect of the project: in it, we could combine all of the experiences of our group of readers as we trained a new, comprehensive virtual reader, whose actions we could observe, record and analyze.
There are, however, a few detriments to using an ANN in this way. First, it comes with a much greater computational overhead than the other classificatory algorithms that I listed above. This overhead makes sense when working with the extremely large data sets that deep learning neural networks have become famous for (millions of images, or billions of words). Any additional overhead in these cases is utterly dwarfed by the size of the data (when you are working with petabytes of data, a few extra megabytes in the model is meaningless). Also, neural networks are the ultimate black boxes: peering beneath the hood reveals the weighting system among the hidden layers of nodes, but, unlike logistic regression, for example, it does not reveal a one-to-one correspondence between a variable and its importance to the classification. Nevertheless, even when taking these into consideration, the advantages of the ANN outweighed the detriments and we set out to train a neural network to identify suspense.
For our initial attempt, I created a set of neural networks using Fritsch and Guenther's package neuralnet in R (https://cran.r-project.org/web/packages/neuralnet/neuralnet.pdf). Although the package allows for the relatively straightforward creation of neural networks trained through backpropagation with the neuralnet() function, it was more expedient to create a set of wrapping functions for training an ANN with the package that could easily be deployed using our data:
This function takes a training set (raw.data), a withheld test sample (test.set) and a vector of column identifiers for both the input features (variable.vec) and the response variables (output.var). The response variables expected by the neural net packages in R are different when compared to other classification models: the neuralnet package expects and classifies on one or more continuous variables. The flag cat=T calls the class.ind() function from a separate package (nnet), which converts a single categorical variable into a binary matrix, where the columns correspond to the levels of the categorical variable as a factor and each row contains a 1 in its corresponding column. In other words, the function converts a single categorical response variable to some number of binary response variables based on how many categorical values were in the initial variable (in this case, 2: suspense and unsuspense). Note that in the training step, the error handling of the function allows the model to fail: this often occurs when the model converges to a local, rather than global, minimum.
The wrapping function above does not just create a neural network model, it also cross-validates that model against the withheld test sample with the function netClass():
The function netClass takes a trained ANN model, a withheld test sample, and a set of correct class assignments. After validating the model by classifying the test sample against the known assignments, it returns the overall error rate for the validation, as well as a classification table and a confusion plot showing the relative classification success for each class. These are returned as part of the output list, along with the trained model, by the trainNeuralNet() function.
Like a topic model that requires a pre-established number of topics, the neuralnet package requires a pre-determined internal structure: some number of hidden levels, each with some number of hidden nodes per level. The training process assigns weights to these nodes, but the actual numbers are fed to the algorithm when it is initialized, here through a vector the same length as the number of hidden levels; the values of each element indicate the number of hidden nodes per level.[4] Determining the number of nodes is highly subjective, particularly for a shallow ANN with a relatively small data set (886 scored passages in our initial sample). In our project, then, we created a series of backpropagation-trained ANNs, varying the number of levels between 1 and 4 and the number of nodes per level between 5 and 8. We iterated each level and node combination 5 times and averaged the error statistics across the iterations (creating, in total, 420 different models). These relatively small networks offered, at least initially, better results than much larger networks, and the small size allowed us to create and store a number of iterations.
In our first results, the best performing network was a simple single-layer neural network with just five hidden nodes. Plotting it, we can easily see its structure (click any image to view the full-resolution version):
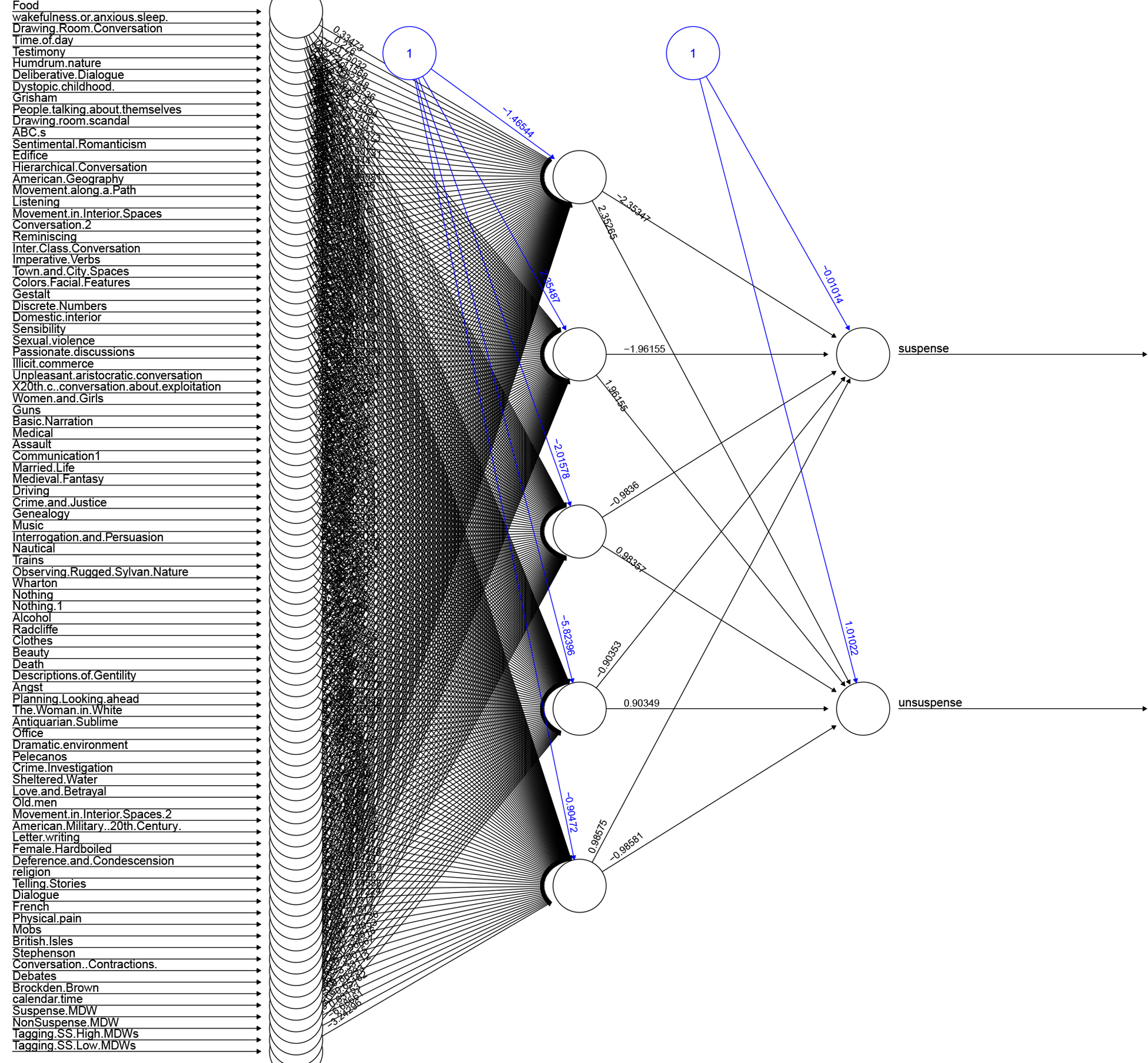
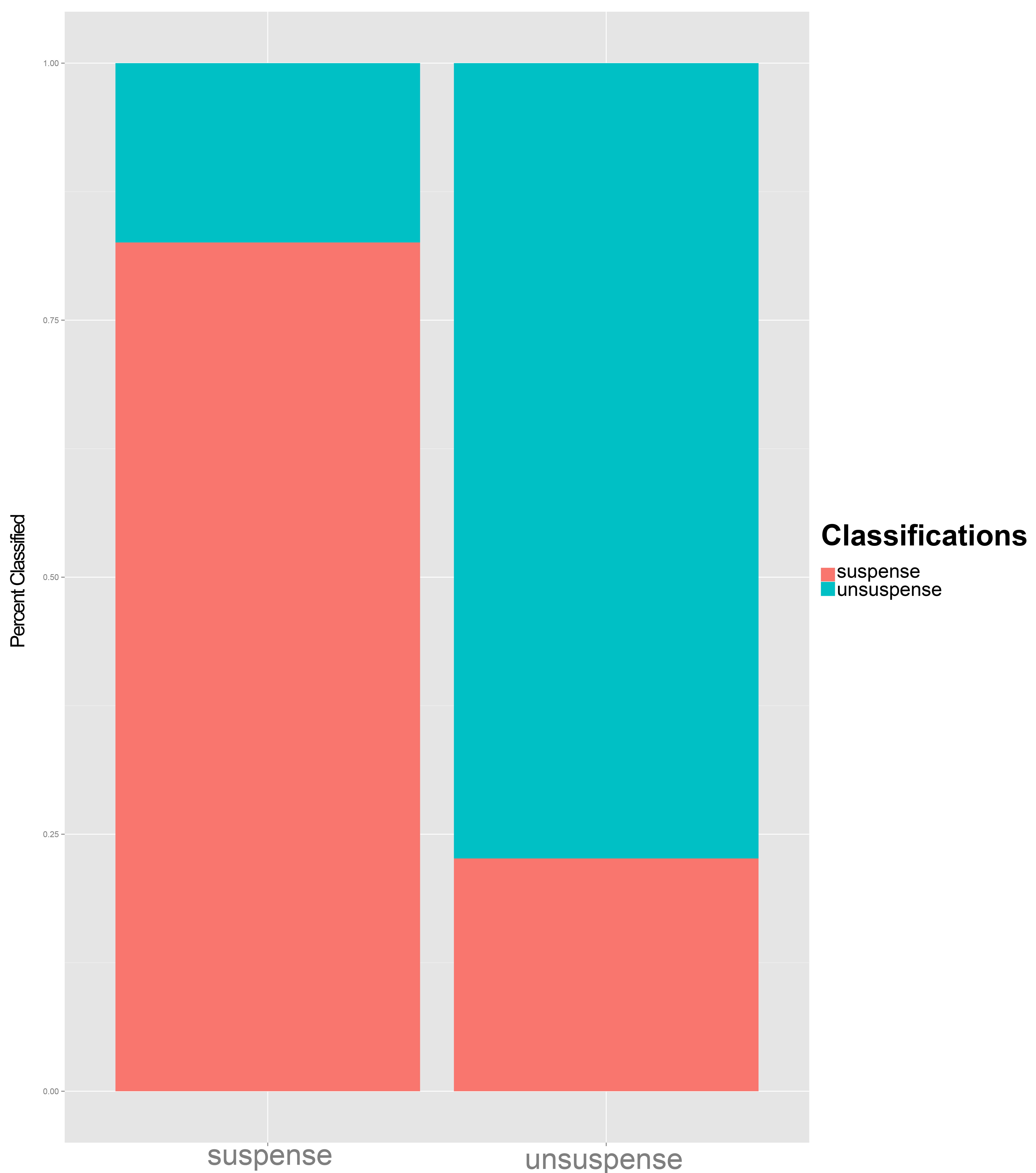
Not only did this success rate outperform logistic regression (65% correct) and SVM (62% correct), but its accuracy overall astonished us. We had expected to observe and draw conclusions from its failures, but here, the successes are far more informative. Based solely on a set of semantic fields, culled from topics models and distinctive words, our virtual reader was able to correctly predict a human rater’s response to a passage four out of five times.
Although one the limitations on using a neural network is our inability to reconstruct the logic behind the weights it assigns to individual nodes (and thus the exact mechanism of its classification decisions), it is still possible to peek into the black box and see the relative magnitude of importance of each variable (if not its precise relationship to the other features or the direction of its weight). And, by bringing our critical understanding of the data to the weights, we can begin to productively unpack the classifier. For the model above, we were able to use a garson plot from the package NeuralNetTools to see the relative importance of each feature in deciding whether a passage was suspenseful or unsuspenseful:
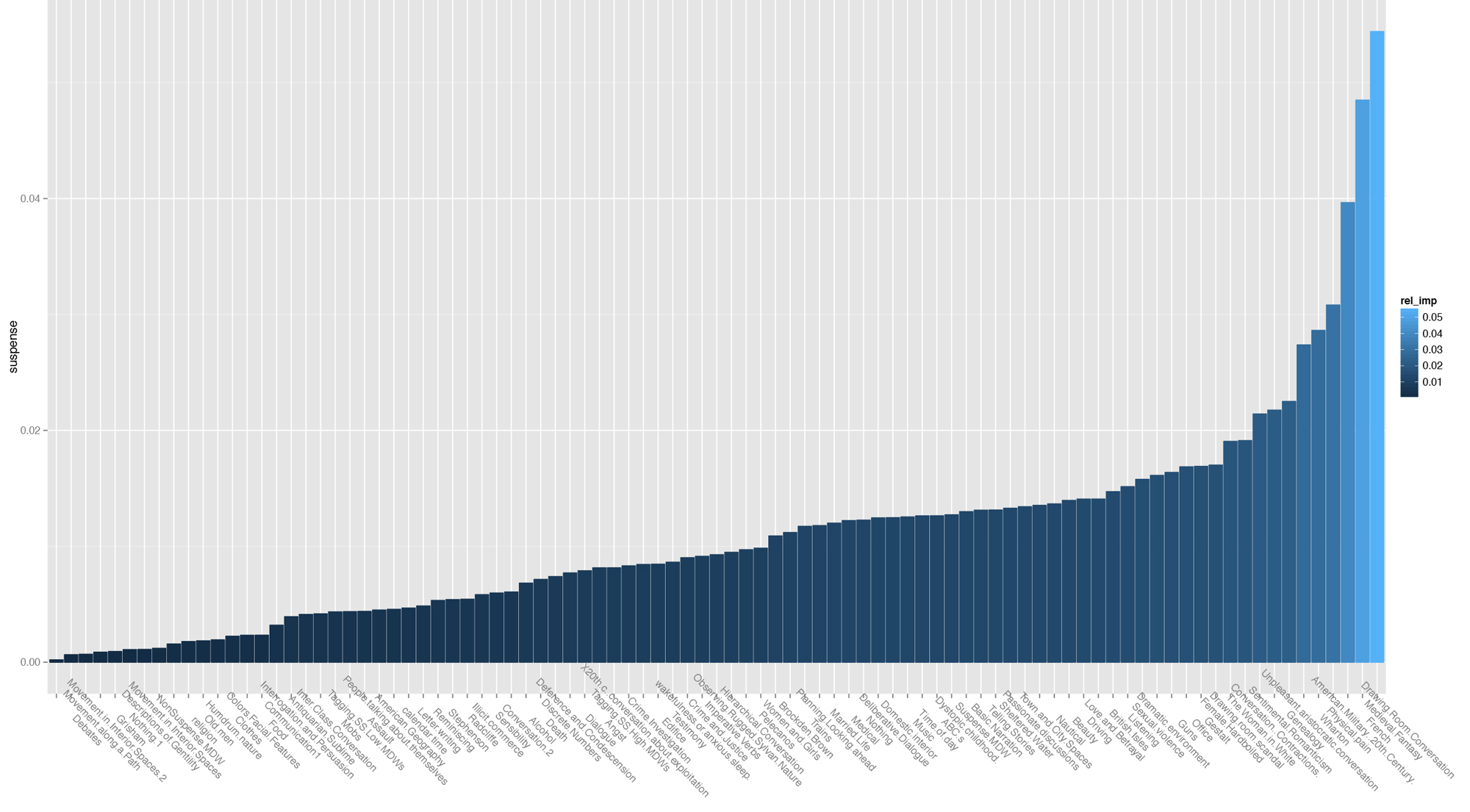
From the neural network then, we were able to not only ascertain that there is a predictive relationship between at least some of the formal features that we identified, and whether the passage was suspenseful or unsuspenseful, but also what features were most strongly associated with suspenseful topics (either in their presence, as we suspect for the topics that we termed “Physical Pain” and “American Military”, or in their absence, as we suspect for “Drawing Room Conversation” or “Sentimental Romanticism”).
The neural network, then, became a virtual participant in the project, an overlay of all of the individual reading experiences of all of the human participants. But it was a participant that was also able to associate patterns of topic and distinctive and difficult word usage with suspenseful or unsuspenseful passages across all of our texts regardless of period or genre. By reading this composite reader, whose level of detail is unmatched by any of our human participants, we were finally able to start drawing the conclusions about the relationship between semantics and suspense that had eluded us during the initial stages of the project. Our unexpected turn from exploratory clusters to supervised classification, from a digitally assisted hermeneutics, to a radically altered meta-observational method, finally provided some answers to many of our initial questions about suspense as a formal property, even as it began to make these questions obsolete by pushing us in new, unlooked for, directions. In this, then, lies both the limits and the promise, the frustration and the excitement, of our work at the Lab.
[1] This, for example is what Stephen Ramsay calls “algorithmic criticism” in his book Reading Machines, when he describes how computational methods “deform” the texts.
[2] Ted Underwood’s recent work using the success and failure of logistic regression to identify genre consistency and identity over time is an excellent example of this process in action.
[3] In ‘measuring’ the features in passages, we abandoned the posterior probabilities of the topic model, or the p-values of the distinctive words and instead calculated the percentages of words in each passage that came from each field, normalizing the results by the expected value of that field in the overall corpus.
[4] So, for example, the vector (9,9,5,5) would describe a network with four hidden levels and nine hidden nodes in each of the first two levels and five nodes in the final two levels.